
혜니니의 공부방
패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 30일차 본문
23.03.21
#패스트캠퍼스 #패캠챌린지 #수강료0원챌린지 #환급챌린지 #직장인인강 #직장인자기계발#패캠인강후기 #패스트캠퍼스후기 #오공완 #강필성의비즈니스데이터분석

으아아 이제 패캠챌린지도 끝! 환급반 성공하기만을 기다려야지. 그래도 나름 열심히 들었던 한달... 아무리 힘들어도 울고싶어도 열심히 들었어유..
강의듣느라 미처 챙기지 못했었는데 교수님의 자료들이 있다. 여기에있는 DSBA 논문 로드맵은 자료는 RSKR 노션이었나.. DSBA 연구실이었나 거기에서 한번 봤었던 로드맵이긴 하지만 정말 정말 유용하고 이거 기반으로 읽을 논문 리스트업 해두기도 했다.


그리고 교수님의 추천 논문 노션까지있다! :) 추가 강의자료들까지 있어서 미리미리 받고 돌아오는 이번 주말 외장하드에 잘 정리해둬야지.. 그래도 사실 이 내용 덕분에 이번에 제안서 작성할 때 이해가 빨랐다. 그래도 논문 보기좋게 줄이는건 넘 어렵다.. 갈길이멀다.ㅠ
오늘도 R 클라우드 켜주자.
해당 링크: https://posit.cloud/content/yours?sort=name_asc
R Studio New project 켜주기.
1. R실습- 의사결정나무.
데이터: 신용대출 이용 고객 예측하기
perf_eval <- function(cm){
# True positive rate: TPR (Recall)
TPR <- cm[2,2]/sum(cm[2,])
# Precision
PRE <- cm[2,2]/sum(cm[,2])
# True negative rate: TNR
TNR <- cm[1,1]/sum(cm[1,])
# Simple Accuracy
ACC <- (cm[1,1]+cm[2,2])/sum(cm)
# Balanced Correction Rate
BCR <- sqrt(TPR*TNR)
# F1-Measure
F1 <- 2*TPR*PRE/(TPR+PRE)
return(c(TPR, PRE, TNR, ACC, BCR, F1))
}> 각각 계산해서. 6가지의 결과물을 리턴받고, 함수가 정의되었음을 알 수 있다.
Post / Pre Pruning 테이블 만들기.
Perf_Table <- matrix(0, nrow = 2, ncol = 6)
rownames(Perf_Table) <- c("Post-Pruning", "Pre-Pruning")
colnames(Perf_Table) <- c("TPR", "Precision", "TNR", "Accuracy", "BCR", "F1-Measure")
Perf_Table>6가지 항목이 모두 0으로 초기화됨.
> 아래는 결과물이다.

Ploan <- read.csv("Personal Loan.csv")
input_idx <- c(2,3,4,6,7,8,9,11,12,13,14)
target_idx <- 10
Ploan_input <- Ploan[,input_idx]
Ploan_target <- as.factor(Ploan[,target_idx])
trn_idx <- 1:1500
CART_trn <- data.frame(Ploan_input[trn_idx,], PloanYN = Ploan_target[trn_idx])
CART_tst <- data.frame(Ploan_input[-trn_idx,], PloanYN = Ploan_target[-trn_idx])> 데이터를 넣고, 전체 데이터를 형변환하여 범주형으로 바꿔준다.
> trn_idx : 임의로 1500개의 데이터를 트레이닝하고, 나머지를 테스트로 가정하는 것.
> CART : 훈련용/학습용으로 나누어서 데이터프레임으로 삽입.
# CART with Post-Pruning 실행하기
install.packages("tree")
library(tree)
# 테스트 모델
CART_post <- tree(PloanYN ~ ., CART_trn)
summary(CART_post)
# 그림이 그려지는 영역 확보, 의사결정 나무가 그려지는 영역 파악가능
plot(CART_post)
text(CART_post, pretty = 1)
#최적의 모델 찾기.
set.seed(123)
CART_post_cv <- cv.tree(CART_post, FUN = prune.misclass)
# 결과
plot(CART_post_cv$size, CART_post_cv$dev, type = "b")
CART_post_cv
# 최종 모델 선택하기
CART_post_pruned <- prune.misclass(CART_post, best = 6)
plot(CART_post_pruned)
text(CART_post_pruned, pretty = 1)
# 예측
CART_post_prey <- predict(CART_post_pruned, CART_tst, type = "class")
CART_post_cm <- table(CART_tst$PloanYN, CART_post_prey)
CART_post_cm
Perf_Table[1,] <- perf_eval(CART_post_cm)
Perf_Table
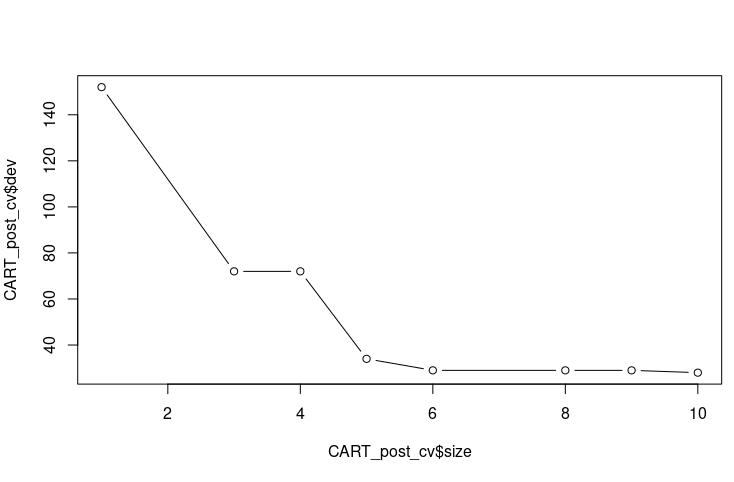
> 의사결정나무 영역을 찾는 의사결정나무 모양 (왼) / 포스트 프루닝을 불순도지표가 어떻게 바뀌는지에 대한 그래프(오)
> Best= 6 이라는 것을 알 수 있다.
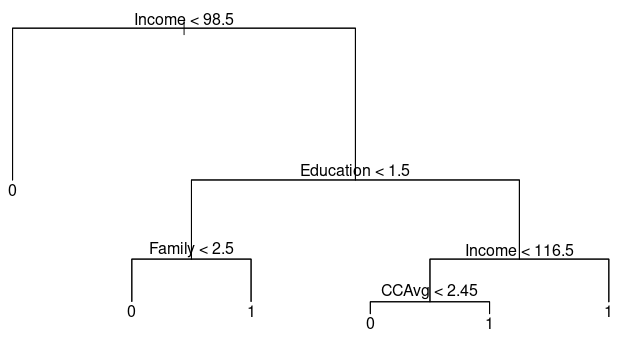
> Post-Pruning을 하고 다시 그려본 의사결정나무 Tree,
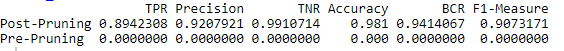
# Pre-Pruning 데이터 모델 돌려보기.
trn_idx <- 1:1000
val_idx <- 1001:1500
tst_idx <- 1501:2500
CART_trn <- data.frame(Ploan_input[trn_idx,], PloanYN = Ploan_target[trn_idx])
CART_val <- data.frame(Ploan_input[val_idx,], PloanYN = Ploan_target[val_idx])
CART_tst <- data.frame(Ploan_input[tst_idx,], PloanYN = Ploan_target[tst_idx])
# 파라미터 세팅하기.
min_criterion = c(0.9, 0.95, 0.99) #기준을가지고 split을했을때 통계적 유효성 검증이 가능한거
min_split = c(10, 30, 50, 100)
max_depth = c(0, 10, 5)
CART_pre_search_result = matrix(0,length(min_criterion)*length(min_split)*length(max_depth),11)
colnames(CART_pre_search_result) <- c("min_criterion", "min_split", "max_depth",
"TPR", "Precision", "TNR", "ACC", "BCR", "F1", "AUROC", "N_leaves")> 데이터를 차근차근 도입하고, 파라미터를 세팅한다, 통계적 유효성 검증과 colnames들로 무엇을 알아보고 저장할 것인지 정의한다.
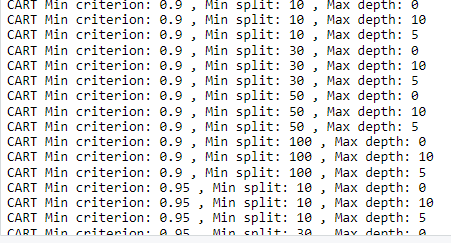
>for문을 넣지 않았지만 약 3번의 긴 for문이 들어간다. 그리고 반복적으로 R이 계산을 진행한다.
# 가장 괜찮은 파라미터 셋 찾기
CART_pre_search_result <- CART_pre_search_result[order(CART_pre_search_result[,10], decreasing = T),]
CART_pre_search_result
best_criterion <- CART_pre_search_result[1,1]
best_split <- CART_pre_search_result[1,2]
best_depth <- CART_pre_search_result[1,3]
# 제일 좋은 트리
tree_control = ctree_control(mincriterion = best_criterion, minsplit = best_split, maxdepth = best_depth)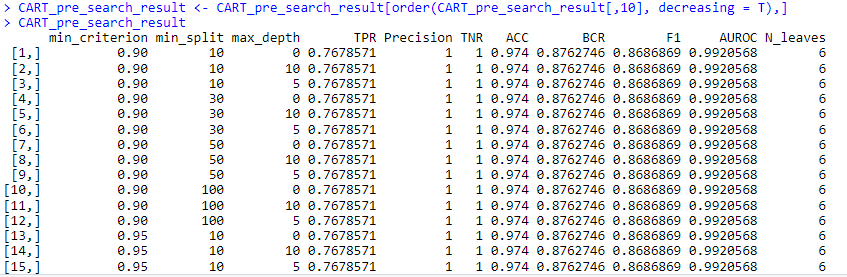
> 위 코드블럭도 계산하면 콘솔창에 이렇게 뜨면서 계산이 진행된다.
# 가장 좋은 트리 모델을 훈련/검증
CART_trn <- rbind(CART_trn, CART_val)
CART_pre <- ctree(PloanYN ~ ., data = CART_trn, controls = tree_control)
CART_pre_prediction <- predict(CART_pre, newdata = CART_tst)
CART_pre_response <- treeresponse(CART_pre, newdata = CART_tst)
# best Tree는?
CART_pre_cm <- table(CART_tst$PloanYN, CART_pre_prediction)
CART_pre_cm
Perf_Table[2,] <- perf_eval(CART_pre_cm)
Perf_Table
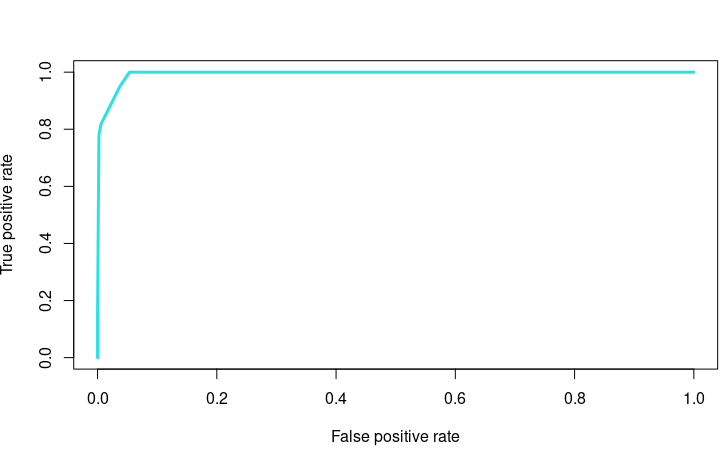
# Plot the ROC
CART_pre_prob <- 1-unlist(CART_pre_response, use.names=F)[seq(1,nrow(CART_tst)*2,2)]
CART_pre_rocr <- prediction(CART_pre_prob, CART_tst$PloanYN)
CART_pre_perf <- performance(CART_pre_rocr, "tpr","fpr")
plot(CART_pre_perf, col=5, lwd = 3)
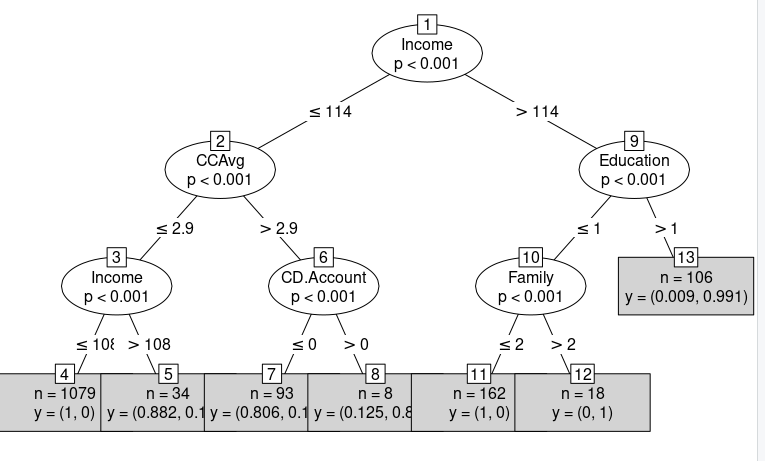
# Plot the best tree
plot(CART_pre)
plot(CART_pre, type="simple")> 해당 내용이 아래 그래프다. #plot the best Tree 결과 (오) 이며 ROC 그래프는 왼쪽이다.
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'공부 기록 > 데이터분석' 카테고리의 다른 글
| 패스트캠퍼스 환급반챌린지 환급 후기 (0) | 2023.05.01 |
|---|---|
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 29일차 (0) | 2023.03.20 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 28일차 (0) | 2023.03.19 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 27일차 (0) | 2023.03.18 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 26일차 (0) | 2023.03.17 |



