
혜니니의 공부방
패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 25일차 본문
23.03.16
#패스트캠퍼스 #패캠챌린지 #수강료0원챌린지 #환급챌린지 #직장인인강 #직장인자기계발#패캠인강후기 #패스트캠퍼스후기 #오공완 #강필성의비즈니스데이터분석

1. K 평균 군집화 K-means Clustering
- > K-평균 군집화 방법은 가장 단순하고 빠른 군집화 방법, 각 군집의 중심위치를 구할 때 해당 군집에 속하는 데이터의 평균(mean)값을 사용하는데서 유래
- 각 군집은 하나의 중심Centroid 를 가진다.
대표적인 분리형 군집화 알고리즘이며, 각 개체는 가장 가까운 중심에 할당되며, 같은 중심에 할당된 개체들이 모여 하나의 군집을 생성한다.
사전에 군집의 수가 K개 정해저야 알고리즘을 실행할 수 있다.
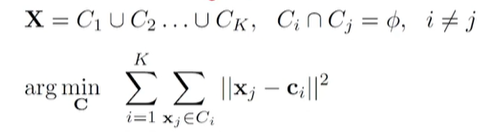
- Hard Clustering vs Soft Clustering
Hard Clustering : 서로 겹치지않는, Non- overlapping 군집 생성, 각 개체는 오직 하나의 군집으로만 할당됨.
Soft Clustering(Fuzzy Clustering): 겹치는 군집 생성하는것도 가능, 한 개체는 여러개의 군집에서 확률적인 할당이 될 수 있다.
- 종류
- 분리형 군집화: 전체 데이터의 영역을 특정 기준에 의해 동시에 구분, 각 개체들은 사전에 정의된 군집 수 중 하나에 속하는 결과를 도출함
- 계층적 군집화: 개체들을 가까운 집단부터 차근차근 묶어가는 방식, 군집화 결과 뿐만 아니라 유사한 개체들이 결합되는 절차dendrogram도 생성할 수 있다.
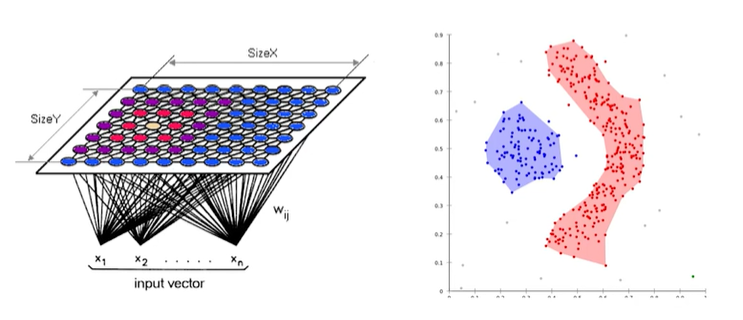
-자기조직화 지도Self-Organizing Map (SOM): 2차원의 격자에 각 개체들이 대응하도록 인공신경망과 유사한 학습을 통해 군집 도출
- 밀도 기반 군집화: 데이터의 분포를 기반으로 높은 밀도를 갖는 세부 영역들로 전체 영역을 구분한다.
별첨_
*위키백과
https://ko.wikipedia.org/wiki/K-%ED%8F%89%EA%B7%A0_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작
ko.wikipedia.org
뭘 가져올까 고민하다가. 역사를 가져와봤어요.
"k-평균"에 대한 개념은 1957년 후고 스테인하우스에 의해 소개되었으나, 용어 자체는 1967년에 제임스 매퀸(James MacQueen)에 의해 처음 사용되었다.현재 사용되고 있는 표준 알고리즘은 1957년에 스튜어트 로이드(Stuart Lloyd)가 펄스 부호 변조(PCM)를 목적으로 처음으로 고안 하였으나 1982년이 되어서야 컴퓨터과학 매거진에 처음 공개되었다.알고리즘이 공개되기 이전인 1965년에 E. W. Forgy 또한 같은 알고리즘을 제안하였다.차후 1975년과 1979년에 Hartigan과 Wong에 의해 거리 계산이 필요하지 않은 좀 더 효율적인 방법이 소개되었다.
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'공부 기록 > 데이터분석' 카테고리의 다른 글
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 27일차 (0) | 2023.03.18 |
|---|---|
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 26일차 (0) | 2023.03.17 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 24일차 (0) | 2023.03.15 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 23일차 (0) | 2023.03.14 |
| 패스트캠퍼스 강필성의비즈니스분석 30일 도전 챌린지! 22일차 (0) | 2023.03.13 |



